

На одному з засідань Міжнародної дослідної асоціації “Добруджа+”, заступник директора Олеся Мельникова зазначила, що орієнтовно у 2010 році визначили початок ери Big Data. У відповідь на це були створені системи підтримки рішень на основі Business Intelligence (DSS BI) орієнтовані на збір і обробку даних із social media (Social media DSS BI). Тому всі передові корпорації повинні мати засоби Social media DSS BI другого чи третього покоління. У цих системах функції Business Intelligence (OLAP, Data mining, ets) повинні бути доступні і аналітикам середньої ланки і первинної ланки – це значно покращить ефективність роботи, ROI.
Grock відповів, що термін Big Data (Великі дані) справді почав активно входити в ужиток і набувати популярності саме приблизно в 2010 році (або трохи раніше/пізніше, залежно від джерела). Багато аналітиків та публікацій вважають період 2009–2012 роками точкою, коли “ера Big Data” стала масово визнаною:
- У 2010 році з’явилися ключові публікації, наприклад, стаття в The Economist “Data, data everywhere” (лютий 2010), де термін “big data” вже використовували як явище, що змінює бізнес, науку та суспільство.
- У 2011 році вийшов відомий звіт McKinsey “Big Data: The next frontier for innovation, competition, and productivity”, який популяризував ідею, що великі дані — це нова хвиля, здатна створювати величезну економічну цінність.
- Багато джерел вказують, що саме на початку 2010-х (після запуску Hadoop у 2005–2006, але з масовим усвідомленням обсягів даних від соцмереж, мобільних пристроїв та сенсорів) відбулося “вибухове” визнання ери Big Data.
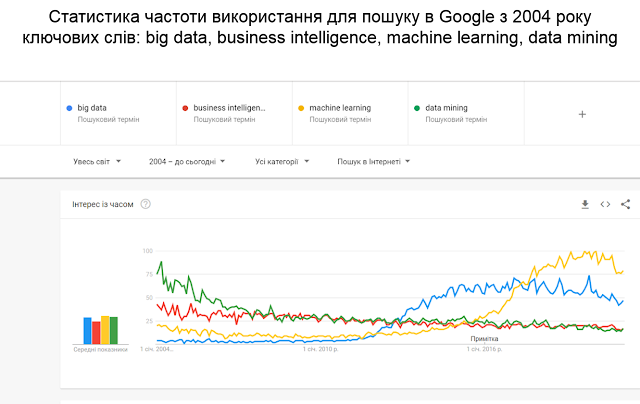
Щодо Business Intelligence (BI): так, саме у відповідь на стрімке зростання обсягів даних (яке традиційні BI-системи вже не могли ефективно обробляти – закреслено нами) почався активний розвиток і трансформація інструментів підтримки рішень.
- Традиційний BI (з 1990-х – 2000-х) добре працював зі структурованими даними в базах даних, але з появою неструктурованих/напівструктурованих даних (соцмережі, логи, сенсори тощо) з’явилася потреба в нових підходах.
- Близько 2010 року багато компаній та аналітиків (Gartner, IDC тощо) почали говорити, що класичний BI “не справляється” з Big Data, тому:
- З’явилися Big Data платформи (Hadoop, Spark тощо),
- BI-системи еволюціонували в Advanced Analytics, Big Data BI, Self-Service BI з інтеграцією великих даних,
- Виникли нові напрямки: Social Media Analytics, Social CRM, Predictive Analytics на базі великих даних.
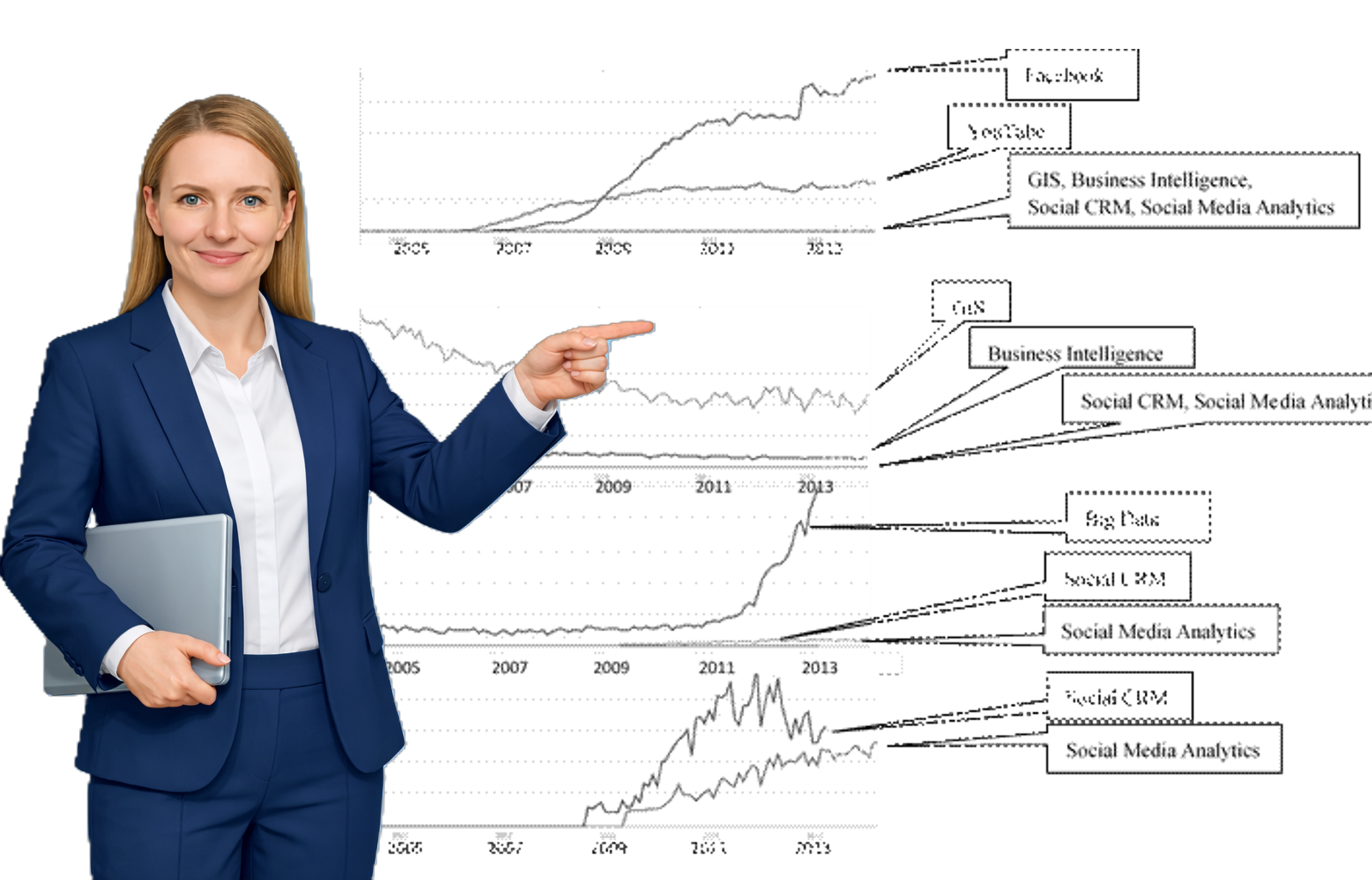
На твоїх графіках (які показують зростання саме з ~2009–2010 років для Social Media Analytics, Social CRM тощо, а Business Intelligence мав стабільніше/раніше зростання) це дуже добре видно: різкий підйом кривих припадає саме на період після 2010-го, коли Big Data став масовим драйвером.Отже, теза Олесі вірна по суті:
- ≈2010 рік — це справді момент, коли суспільство/бізнес масово усвідомили “еру Big Data”,
- і саме як реакція на це традиційний BI почав трансформуватися/доповнюватися новими інструментами для роботи з великими та різноманітними даними.
Якщо коротко: так, 2010-й — це слушна орієнтовна дата для початку “ери Big Data” і відповідного буму в еволюції систем підтримки рішень на базі BI. Графіки це чудово ілюструють!
Я додам, що офіційно початок big data age визначили саме у 2010 році у доповіді PCAST про цифрове майбутнє президенту США Бараку Обамі. Студенти ЖВІ НАУ перекладали цей звіт (біля 100 сторінок) по частинам – на українську мову. Було встановлено, що ми йдемо у вірному напрямку у розвитку засобів аналізу big data.
Залишити коментар до Igor Krukovsky Скасувати коментар